Ahogy az SQL Server 2016 esetén is, itt is megvan a kedvenc új funkcióm. A 2016-os verzió esetén a partíció szintű truncate table volt, itt most azt online resumable index lett. Miért is ez lett? Sok okom van:
- FULL recovery modelt használok éles környezetekben a legtöbb esetben. Ebből következik, hogy tranzakciós log mentést is csinálni kell.
- Előfordult már, hogy megtelt a log meghajtó (nem, nem akarok róla beszélni :) ), ami egy hosszan futó tranzakció miatt volt.
- Az index rebuild egy nagy tranzakció, sokáig tarthat, a leállítás inkább problémát generált, mintsem hasznot hozott volna.
Ezek mentén már érthető lehet, miért lett a kedvencem:
- megállítható az index rebuild,
- nincs az, mint a régebbi verzióknál, hogy meg kell várni az index rebuild visszavonását, rollback-jét,
- a tranzakciós log mentés is hasznos tud lenni, mert engedi az un. log truncate-et (ami ugye nem az, hogy visszaadjuk az OS-nek a lemezterületet, hanem csak a VLF státuszát állítja 2-ről - aktív - 0-ra - inaktívra).
Azért ez az első verzió, szóval vannak benne furcsaságok, de lesz ez jobb is. Ezek után lássuk, hogyan is működik.
Demó környezet beállítása
A demóhoz szükségünk van a WideWorldImporters adatbázisra, amit a https://github.com/Microsoft/sql-server-samples/tree/master/samples/databases/wide-world-importers oldalról lehet letölteni. Itt elég jól dokumentált, hogyan is kell feltenni. Miután megvan az adatbázis át kellene váltani FULL recovery modelre, majd egy FULL és tranzakciós log mentést is kell csinálni. Ezt az alábbi kód segítségével el lehet végezni:
USE [master]
GO
ALTER DATABASE [WideWorldImporters] SET RECOVERY FULL
GO
BACKUP DATABASE [WideWorldImporters] TO DISK = N'nul'
GO
BACKUP LOG [WideWorldImporters] TO DISK = N'nul'
GO
A mentések nul device-ra mennek, azaz nem lesz a diszken mentés, szóval óvatosan!
Válasszunk indexet
Nem, ez nem autókereskedés és extra választás :), hanem egy index, amit újra fogunk építeni. Ez legyen a Sales.OrderLines tábla clustered indexe. Ennek nézzük meg néhány adatát: mennyi sor van és mennyi page-en van tárolva.
USE [WideWorldImporters];
GO
SELECT [o].[name] AS [table_name],
[i].[name] AS [index_name],
[p].[index_id],
[au].[type_desc],
[au].[used_pages],
[p].[rows]
FROM [sys].[allocation_units] AS [au]
JOIN
[sys].[partitions] AS [p] ON [au].[container_id] = [p].[hobt_id]
JOIN
[sys].[objects] AS [o] ON [o].object_id = [p].object_id
LEFT JOIN
[sys].[indexes] AS [i] ON [i].object_id = [p].object_id
AND [i].[index_id] = [p].[index_id]
WHERE [p].object_id = OBJECT_ID('[Sales].[OrderLines]')
AND [i].[index_id] = 1;
Látható, hogy 5115 page és 231412 sor van az én esetemben. Ez elegendő lesz a demóhoz.

Tranzakciós log
Itt kezd érdekes lenni a dolog. Nézzük meg, hogy a tranzakciós logban a VLF-ek milyen állapotban vannak. Ehhez mindjárt három scriptet is adok: az első a régi módszer, ami SQL Server 2017 előtti verziókban is működik, a másik kettő új DMV.
DBCC LOGINFO('WideWorldImporters')
Ez az alábbi eredményt adja vissza:
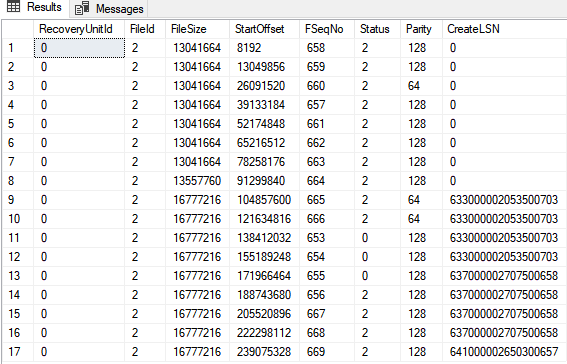
Látható, hogy 17 VLF van, amiből 14 aktív, Status = 2
Ugyan ezt egy új DMV-ből is le lehet kérdezni:
SELECT * FROM sys.[dm_db_log_info](DB_ID('WideWorldImporters'));
GO
Ennek az eredménye az alábbi lett:
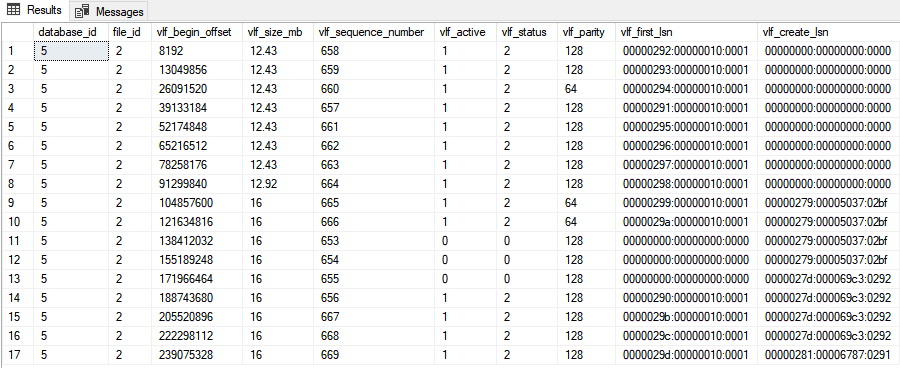
Nagyjából ugyan az látható, mint a régi verzió esetén, de azért van pár hasznos új információ is. Ezekről később, a lényeg itt is a státuszon van. Ha nem akarom ennyire részletesen megnézni a logot, csak az aktív VLF számok érdekelnek, akkor van egy harmadik megoldás is, amit az alábbi lekérdezés mutat meg:
SELECT [dm_db_log_stats].[database_id],
[dm_db_log_stats].[recovery_model],
[dm_db_log_stats].[total_vlf_count],
[dm_db_log_stats].[total_log_size_mb],
[dm_db_log_stats].[active_vlf_count],
[dm_db_log_stats].[active_log_size_mb],
[dm_db_log_stats].[log_truncation_holdup_reason],
[dm_db_log_stats].[log_since_last_log_backup_mb],
[dm_db_log_stats].[log_since_last_checkpoint_mb]
FROM [sys].[dm_db_log_stats](DB_ID('WideWorldImporters'));
GO
Ennek az eredménye alább:

Itt érdemes megfigyelni az active_vlf_count és a total_vlf count oszlopot. Ezekhez az értékekhez még vissza fogok térni.
Index rebuild
Akkor most építsük újra az indexet, de menet közben állítsuk is meg. Amit fontos megemlítenem rögtön az elején, hogy a megállítás csak az online rebuild esetére igaz, ha ezt nem adjuk meg, akkor hibát kapunk, illetve látni fogjuk, hogy miért is érdekes ez a későbbiek során.
ALTER INDEX [PK_Sales_OrderLines] ON [Sales].[OrderLines]
REBUILD WITH(ONLINE = ON, RESUMABLE = ON);
GO
Vegyük észre a RESUMABLE = ON kapcsolót. Ettől lesz megállítható és újraindítható az index rebuild. Elindítás után, egy másik query ablakban a következő kóddal álítsuk meg, függesszük fel az index rebuild műveletet:
ALTER INDEX [PK_Sales_OrderLines] ON [Sales].[OrderLines] PAUSE;
GO
Ennek hatására az index rebuild leállt, ráadásul kaptunk egy gyönyörű hibaüzenetet. Ez nem bug, hanem feature :)
Msg 1219, Level 16, State 1, Line 49
Your session has been disconnected because of a high priority DDL operation.
Msg 1219, Level 16, State 1, Line 49
Your session has been disconnected because of a high priority DDL operation.
Msg 596, Level 21, State 1, Line 48
Cannot continue the execution because the session is in the kill state.
Msg 0, Level 20, State 0, Line 48
A severe error occurred on the current command. The results, if any, should be discarded.
Ez csak annyit jelent, hogy fel van függesztve az index rebuild, semmi komoly :). Remélhetőleg ezen lesz még faragva, mert így eléggé ijesztő azért.
Felfüggesztett index rebuild állapota
Most, hogy megállítottuk az index újraépítést, nézzük meg ennek az állapotát egy másik DMV-ben:
SELECT *
FROM [sys].[index_resumable_operations];
GO

Látható, hogy 46%-ban végzett az index újraépítéssel, illetve PAUSED állapotban van. Ez szuper.
Már megint a tranzakciós log
Nézzük meg ismét a tranzakciós logot, hogy mit látunk:
SELECT [dm_db_log_stats].[database_id],
[dm_db_log_stats].[recovery_model],
[dm_db_log_stats].[total_vlf_count],
[dm_db_log_stats].[total_log_size_mb],
[dm_db_log_stats].[active_vlf_count],
[dm_db_log_stats].[active_log_size_mb],
[dm_db_log_stats].[log_truncation_holdup_reason],
[dm_db_log_stats].[log_since_last_log_backup_mb],
[dm_db_log_stats].[log_since_last_checkpoint_mb]
FROM [sys].[dm_db_log_stats](DB_ID('WideWorldImporters'));
GO

Az eddigi 17 VLF-ből 21 lett és a 14 aktív is 19-re nőtt, nem mellékesen a méret is növekedett. Ugye eddig a tranzakciós log truncate nem ment index rebuild esetén, felfüggeszteni meg nem igazán tudtuk eddig. Akkor most képzeljük el, hogy azért függesztettük fel, mert a lemez területből majdnem kifogytunk és fontos, hogy a tranzakciós logban a VLF-ek újra legyenek írva. Ehhez csinálok egy tranzakciós log mentést.
BACKUP LOG [WideWorldImporters] TO DISK = N'nul'
GO
Processed 10664 pages for database 'WideWorldImporters', file 'WWI_Log' on file 1.
BACKUP LOG successfully processed 10664 pages in 0.072 seconds (1157.070 MB/sec).
Ennek eredménye, hogy 10664 page ki lett írba a logból, illetve a VLF-ek is inaktívvá váltak, ahol nem volt aktív tranzakció. Vajon igaz ez? Nézzük meg a mentés előtt használt script segítségével:

Látható, hogy megtörtént a log truncate: a log mérete nem változott, de az aktív VLF-ek száma csökkent! Ez eddig nem volt lehetséges, csak az SQL Server 2017-es verzióban van erre lehetőség (a bejegyzés írásának időpontjában).
Hol van a "félkész" indexem?
Jogos a kérdés. Vajon hova rakja az SQL Server a "félkész" indexemet? Amikor megkérdeztem kollégákat erről, mindenki a tempdb-re szavazott első felindulásból, de amikor újraindítottam a szervert és úgy is befejeződött az újraindított index rebuild, akkor azért gondolkodóba estek. Ugye az elején írtam, hogy csak az ONLINE = ON kapcsolóval együtt működik a dolog. Az online index művelet esetén egy "másolatot" készít az eredeti index alapján, azaz a meglévő index mellé fogja tárolni. Valóban? Lássuk csak:
SELECT [o].[name] AS [table_name],
[i].[name] AS [index_name],
[p].[index_id],
[au].[type_desc],
[au].[used_pages],
[p].[rows]
FROM [sys].[allocation_units] AS [au]
JOIN
[sys].[partitions] AS [p] ON [au].[container_id] = [p].[hobt_id]
JOIN
[sys].[objects] AS [o] ON [o].object_id = [p].object_id
LEFT JOIN
[sys].[indexes] AS [i] ON [i].object_id = [p].object_id
AND [i].[index_id] = [p].[index_id]
WHERE [p].object_id = OBJECT_ID('[Sales].[OrderLines]')
AND [i].[name] IS NULL;
GO

Már a szűrési feltételekben ellőttem, hogy mi alapján találom meg alapvetően: az index neve NULL, illetve az index_id is messze egy olyan szám, amit nem is vehetne fel. Ennek részletezésébe most nem mennék bele, a lényeg, hogy ott van a "félkész" indexem az adatbázisban, ahol az eredeti indexem is van.
Akkor most fejezzük be az index újraépítést
Ehhez nem kell mást tenni, csak az alábbi parancsot kell futtatni:
ALTER INDEX [PK_Sales_OrderLines] ON [Sales].[OrderLines] RESUME
Amint ezt lefutott, az index rebuild onnan folytatta, ahol abbahagyta és a tranzakciós logunk is kezelhető maradt.
Összegzés
Szerintem ez egy nagyon jó funkció, nagyon sok kellemetlen dolgot ki lehet kerülni vele, de legalább ugyan ennyit is lehet generálni :). Több kérdés is felmerülhet még ezzel kapcsolatban, hogy mi van akkor, ha sok update van a táblán, stb. Ezekbe most nem mennék bele, az már egy hosszabb történet. Remélem ettől függetlenül másoknak is hasznos lesz ez a funkció.